

To meet the challenges posed by very strong growth on a European scale, SAFTI migrated its entire infrastructure to the AWS Cloud. This migration made it possible to meet the needs for scalability, flexibility and speed of the company’s infrastructure and development.
From the preparation of the migration to the methodology, including the challenges of internalizing Cloud skills and raising team awareness, what are the key factors that made this project successful? In this article, Tommy Vinhas, Cloud&DevOps Architect, answers our questions about this migration.
4th French real estate network and 2nd agent network, SAFTI has 5,500 advisors in France, and is also present in Spain, Portugal and Germany. The SAFTI independent network benefits from digital solutions developed largely internally, in Toulouse, by a tech team of 70 people.
The growth of SAFTI at the European level has led to a strong evolution in the needs of the teams, both in terms of infrastructure and development.
On the infrastructure side, the company needed to be able to scale up more quickly, reduce the complexity of maintaining and evolving the fleet, reduce maintenance times , and overall reduce the burden of maintaining operational condition. The infrastructure teams also wanted to move towards infrastructure as code, and benefit from the advantages of automation, reliability and replicability .
On the development side, the teams needed to be able to test faster . And to do this: reduce the CI/CD bottleneck during usage peaks, reduce the technological gap between the developer’s workstation and production, and make developers more autonomous.
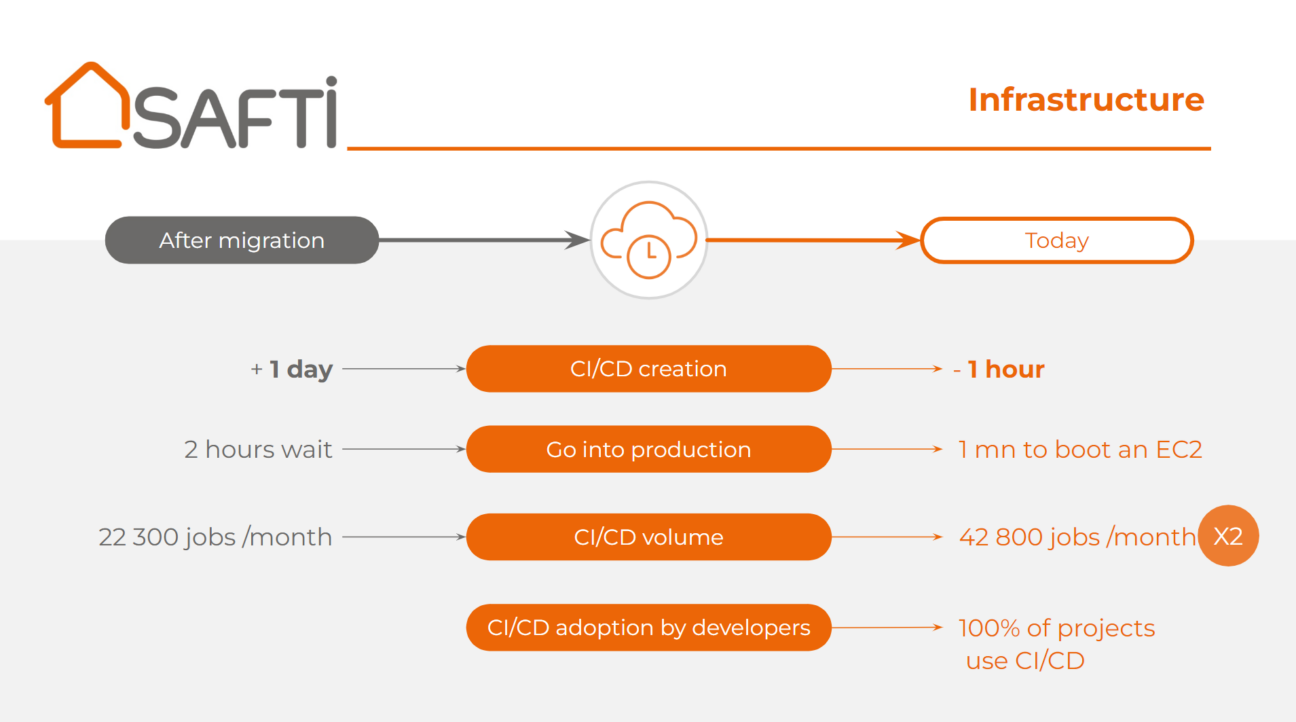
It is to meet all of these needs that SAFTI has chosen to migrate to the AWS Cloud. The gains observed following the migration are impressive:
- Creation of a CI/CD: 1 day -> 1 hour
- Production start-up: 2 hours -> 1 minute
- Today 100% of projects have CI/CD
On the infrastructure side, the migration implemented the following elements: creation of an AWS Landing Zone with multi-account architecture and centralized AWS SSO authentication, Kubernetes EKS clusters, use of Karpenter for node management (horizontal scaling), IAC & architecture with Terraform, and orchestration of Terraform CI/CD.
Interview Tommy Vinhas – Cloud&DevOps Architect
What were the goals of migrating to AWS?
SAFTI is growing very strongly, so we needed scalability that a traditional provider could not offer us. We wanted to be able to adapt the size of our infrastructure according to our needs, and to be able to increase or decrease the number of resources ( scale up/down ).
This migration covered the entire scope of the IS – all web hosting is migrated to AWS.
How did you prepare for the migration, from a technical and human point of view?
Devoteam Revolve supported us with the setup and design of the Landing zones , then we recruited to lead the migration internally: we looked for qualified profiles, with good experience of the AWS Cloud.
On the technical side, we established an inventory of our resources, applications and services internally, then we attached them to AWS services when they existed. When there was no equivalent service, we defined a migration roadmap , based on our objectives for the application/service, possible areas for improvement, and AWS managed services that could meet our needs. For example, we chose the Kubernetes EKS orchestrator on AWS, for others we started classic machines.

Is recruiting qualified profiles a challenge?
Finding experienced profiles on AWS and Kubernetes, yes it is clearly a challenge, these are rare profiles. It is all the more complicated as the market is tense in the Toulouse area, with large aeronautical or automobile groups facing some of the talent.
We therefore quickly changed our recruitment strategy , to look for qualified people on AWS or Kubernetes; we also focused on our technological progress; when recruiting, we were 6 months ahead of the migration with the internal team. We set up a small onboarding during recruitment: presentation of technical advances to candidates, inventory and medium/long term vision. For a candidate, it’s a challenging context, and it’s interesting to know what you’re getting into.
This approach worked well, we found 3 collaborators quite quickly, after 6 months of searching with a traditional organization. Everything came together when we reviewed our recruitment process.
In this context of migration, how does the onboarding of new employees take place?
We favored recruiting people who seemed very involved to us: I prefer someone less qualified, but with a strong desire to learn and get involved in a migration and continuous improvement project. During onboarding, we made sure to make each new employee excel in their field . A Kubernetes profile thus begins with 3 to 4 months solely on Kubernetes EKS subjects. After which, we know that he is completely “trained”, and that he will be able to onboard someone else. Cloud profiles immediately start putting into production and working on complex subjects.
In this way, these two types of profile become excellent in their domain, and we can then increase their skills in the complementary domain, AWS or Kubernetes EKS. We formed pairs , and we revised the costing of the projects upwards: we started from the principle that 30 to 40% of the “knowledgeable person’s” time would be devoted to helping the other to improve their skills. Today we still have this type of organization in pairs for code review, or on architectural design tasks. The more experienced person guides the other.
What gains do you see following migration?
We are now at 5 to 7 production releases per day, in build, and 2 to 3 in production. Going into production is no longer a blocker, but a positive goal. This is one of the benefits of the Cloud: production releases are more frequent, and we have much more perspective because we do more tests beforehand. Being able to deliver much more often is a real benefit. This means that the review codes are smaller (on average 15 lines), and therefore we take little risk in putting them into production.
At the level of my team, we have gained peace of mind regarding the evolution of the platform.
From a more global point of view, there is also a performance gain , we can now do horizontal scaling and absorb load peaks which would not have occurred on our old infrastructure. A TV advertising campaign generates thousands of requests in the minutes following the broadcast: today we can launch this type of campaign with confidence. Visitation to our public site has also increased significantly, and we can now accommodate more than 110 million requests per month, and absorb large load peaks without impacting the quality of service.
Finally, at the IT department level, we benefit from greater flexibility to test products or set up POCs quickly. We were thus able to carry out a POC on an AI subject in 2 weeks, and put it into production in 6 weeks. Before the migration, we would not have been able to carry out this project, at least not in this budget or in this time frame.
What are the lessons of this migration?
We decided to migrate the less critical loads first, on a large scale. We migrated all our CI/CD, i.e. 50,000 pipelines/month, which used 2000 machines. The migration allowed us to optimize and reduce the number of machines. And this first wave of migration allowed us to test the tools, the monitoring, estimate our responsiveness, and the effectiveness of our PRA on non-critical loads. It was the right choice, after 6 months we had a good perspective on what was working and what was not, on our processes, our backups, the training of the team, etc.
Based on this experience, we took stock of our strengths and weaknesses before moving on to production workloads. This is what allowed the production migration to go smoothly.
We also had difficulties, partly due to level differences in the team, and partly to the orchestration of the different Cloud bricks. The public Cloud requires interconnecting many bricks, network, DNS, load balancer, so getting started was a little complicated. For us, this was the main problem to address before being able to migrate production.

What are the other points to watch out for?
The difficulty of changing the overall commitment of the IT department teams should not be underestimated. Most often, a migration only concerns the infrastructure team, but Cloud migration also impacts developers because it changes the way they work. We must therefore succeed in getting developers on board and training them on how the Cloud works. For this, we were fortunate to be well supported by the lead developers who circulated information, organized talks and events. The human aspect is more complex to manage in a migration; it requires awareness-raising and training efforts.
From a technical point of view, we must also take into account the question of legacy, and make trade-offs: is it relevant to invest 30 days in legacy which will be migrated in 5 months?
How did Devoteam Revolve support you in preparing for the migration?
We needed support on the setup of migration and Landing Zones . Devoteam Revolve has carried out several workshops on Landing Zones, so that our teams can then take up the subject and make it their own. The workshops also covered all associated topics: Terraform, infra as code, CI/CD , etc.
We contacted Devoteam Revolve for the technical excellence of its stakeholders, we wanted to be supported by specialists. The Devoteam Revolve team assessed our needs, the volume, and where we wanted to go, then designed the Landing Zone to meet the demand. This support allowed us to make trade-offs, to find the right balance between the complexity of the architecture and our real needs. This is something you can’t do if you don’t have Cloud experience, and it saved us several weeks of work.

