


Le Bon Coin, Expedia, Glassdoor, Deezer, The New York Times, L’Oréal… toutes ces entreprises ont comme point commun de gérer un grand volume de pages web. Afin d’optimiser leur référencement dans les moteurs de recherche, elles font appel à Botify : l’entreprise crawle 5 milliards de pages par mois, soit plus de 2 petabytes de données. Pour accélérer le temps de développement et de mise en production de ses modèles de Machine Learning, l’équipe Data Science de Botify a élaboré en collaboration avec Devoteam Revolve une solution basée sur Amazon SageMaker Pipelines.
Cet article propose un compte-rendu du talk « Passez à la vitesse supérieure avec Amazon Sagemaker Pipelines » donné au Summit AWS Paris du 12 Avril 2022, par Yanal Wazaefi (Botify), Fabien Lallemand (Devoteam Revolve) et Jamal Aourraz (Devoteam Revolve).
Comme l’a expliqué Yanal Wazaefi, Head of Data Science Botify, ces dernières années les moteurs de recherche rencontrent des difficultés pour recenser l’ensemble des pages Web. Le contenu a explosé en volume, et les moteurs de recherche peinent à interpréter le contenu dynamique des pages. Certains sites ont ainsi des dizaines de millions de pages, comme Le Bon Coin, Carrefour, ou Fnac Darty, et Botify propose à ces entreprises des solutions pour optimiser techniquement leurs sites, faciliter l’indexation et donc optimiser le référencement naturel, ou Search Engine Optimization (SEO).

Accélérer les mises en production des modèles
Les équipes de Data Scientists de Botify travaillent pour générer des recommandations intelligentes et optimiser le référencement en utilisant des algorithmes de Machine Learning, de Natural Language Processing, ou des statistiques avancées. Le cycle de projet est relativement classique : les Data Scientists explorent et prototypent dans des notebook Jupyter, ils valident ensuite leurs résultats avec les experts métiers et SEO, puis ils collaborent avec les ingénieurs chargés de l’intégration de ces solutions dans les workflows, qui sont basés sur le service AWS Simple Workflow.
Ce cycle de projet pouvait prendre jusqu’à plusieurs mois et l’équipe Botify souhaitait aller plus vite, et pouvoir :
- Itérer pour tester les nouveaux modèles
- Disposer de plusieurs environnements
- Mettre en place une intégration continue
- Monitorer les pipelines
- Suivre les performances des modèles
L’entreprise a fait appel à l’équipe Devoteam A Cloud pour les aider à trouver une solution à ces problématiques

Yanal Wazaefi, Head of Data Science Botify
Les contraintes du Machine Learning en production
Pour Fabien Lallemand, Devoteam Revolve, il est essentiel de clarifier ce qu’on entend par “machine learning en production”. De nombreuses entreprises pensent avoir du ML en production avec un cas d’usage qui tourne sur le poste d’un Data Scientist, mais le plus souvent beaucoup d’actions, comme la récupération des features, doivent être faites manuellement.
On parlera ici de mise en production au sens IT du terme, et c’est une phase du projet qui implique trois équipes distinctes, Data Scientists, ingénieurs logiciels, et Ops, avec des objectifs différents et parfois contraires, et qui pourtant doivent collaborer vers un objectif commun. La difficulté est de gérer ce partage des contraintes entre les différentes parties.
C’est le concept du ML Ops :

Dans le cas d’un pipeline classique de Machine Learning, le principal problème rencontré lors du passage en production était la scalabilité : ce qui fonctionnait avec un petit dataset ne passait plus avec l’intégralité des données en production. Aujourd’hui ce point est géré nativement par la plupart des algorithmes, mais il reste quatre points à adresser :
- L’intégration dans l’écosystème IT : comment faire de l’algorithme une application
- La préparation de la donnée : la feature va être utilisée au moment de l’entraînement du modèle mais aussi au moment de l’inférence temps réel, durant laquelle les temps de réponse doivent être beaucoup plus courts.
- La détection des performances : pouvoir détecter les baisses de performance du modèle en production qui sont dues à des causes extérieures (par exemple la détection des visages qui ne fonctionne plus à cause des masques Covid)
- La standardisation et la généralisation du pipeline de ML.
Sur ce dernier point, Amazon SageMaker Pipelines amène une standardisation et permet de traiter de la même manière un algorithme supervisé ou non supervisé, ou par exemple de traiter un cas d’usage de détection d’image. Tout sera packagé avec la même interface et on aura donc un pipeline de livraison homogène.
Amazon SageMaker Pipelines amène une standardisation et permet de traiter de la même manière un algorithme supervisé ou non supervisé.
Par ailleurs, quand il faut ré-entraîner le modèle, on doit repasser par l’ensemble des environnements (développement, pré-production, production…). Dans le cas de Botify, le développement d’une solution basée sur Amazon SageMaker Pipelines permet maintenant de livrer la mécanique globale de ré-entraînement du modèle, plutôt que de livrer simplement le modèle. Cette méthode et la livraison du pipeline permet à Botify de disposer d’une chaîne unique pour reconstruire le modèle pour chacun des cas d’usage.
Architecture de la solution
Quels composants AWS ont été utilisés pour répondre au besoin de Botify ?
L’éco-système se base sur Amazon SageMaker et plus particulièrement sur SageMaker Pipelines et SageMaker Model Registry. Ce projet, mené en 2021, a été l’un des premiers en France à tirer parti de Sagemaker Pipelines, qui à ce moment venait tout juste de passer en general availability. SageMaker Pipelines est la solution ML Ops d’AWS, et apporte les pratiques et process DevOps appliqués au Machine Learning.
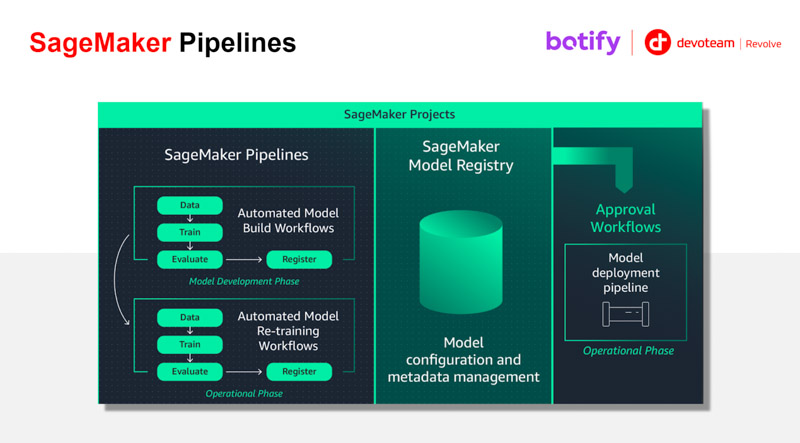
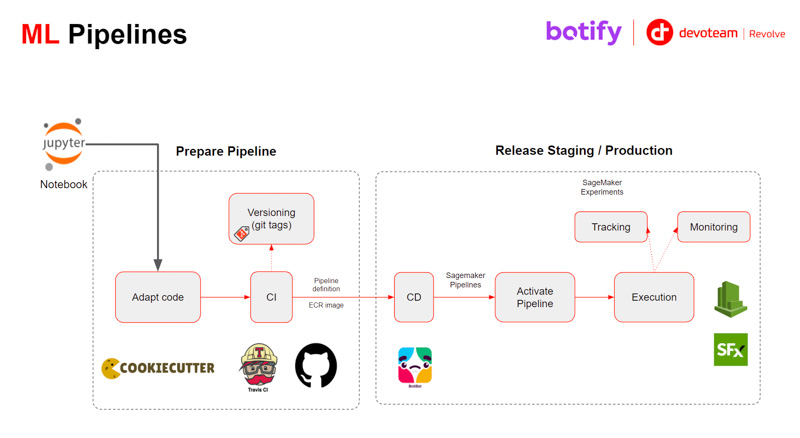
La solution développée autour d’Amazon SageMaker Pipelines a permis de répondre aux objectifs de Botify :
- Assurer la scalabilité
- Réduire le temps de mise en production
- Donner de l’autonomie aux Data Scientists
Aujourd’hui l’équipe Data Botify a triplé ses effectifs, et a pu ajouter plus de 100 « smart features » à ses solutions.

